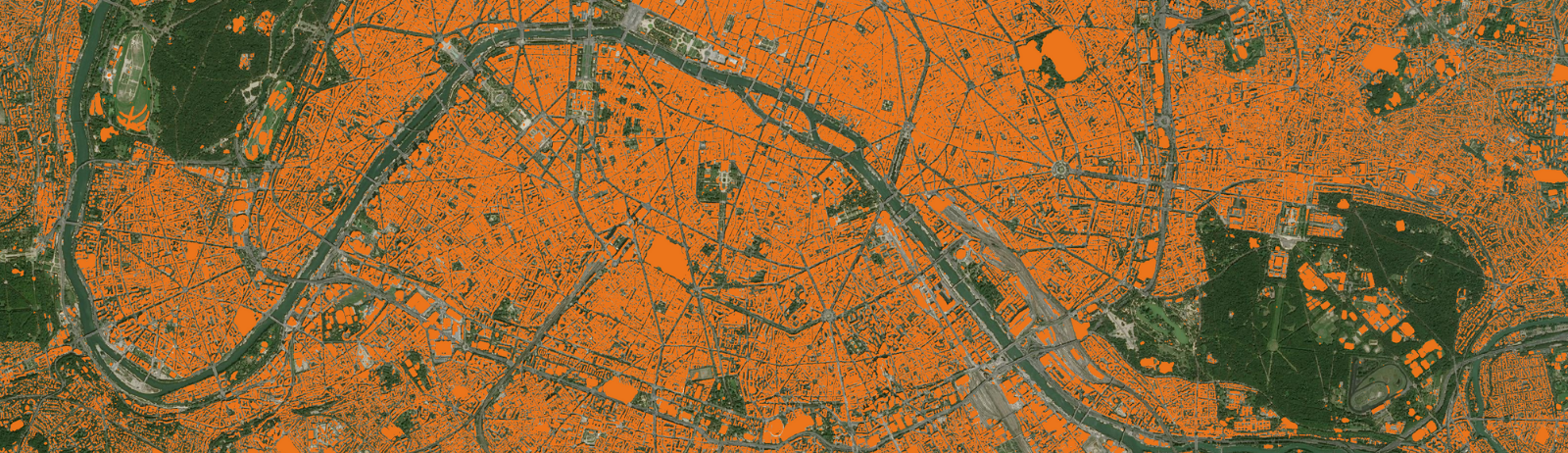
Accès au produit
Présentation
Le CES Urbain propose le produit « Empreinte au sol des bâtiments » (Buildings Footprint) sur toute la France métropolitaine, a une résolution spatiale de 1.5 m. Il sera élaboré chaque année à partir des images satellitaires à très haute résolution Spot-6 et Spot-7 diffusées par le pôle Theia via le portail de DINAMIS.
Le produit est issu du traitement des images par un réseau de neurones artificiels profond, entraîné à partir de millions d’extraits d’images Spot-6 et Spot-7, et de la BDTOPO IGN. Toutes les images satellitaires diffusées par DINAMIS et acquises entre 2015 et 2019 ont été utilisées pour entraîner un modèle unique, capable de classifier n’importe quelle image sur le territoire français métropolitain.
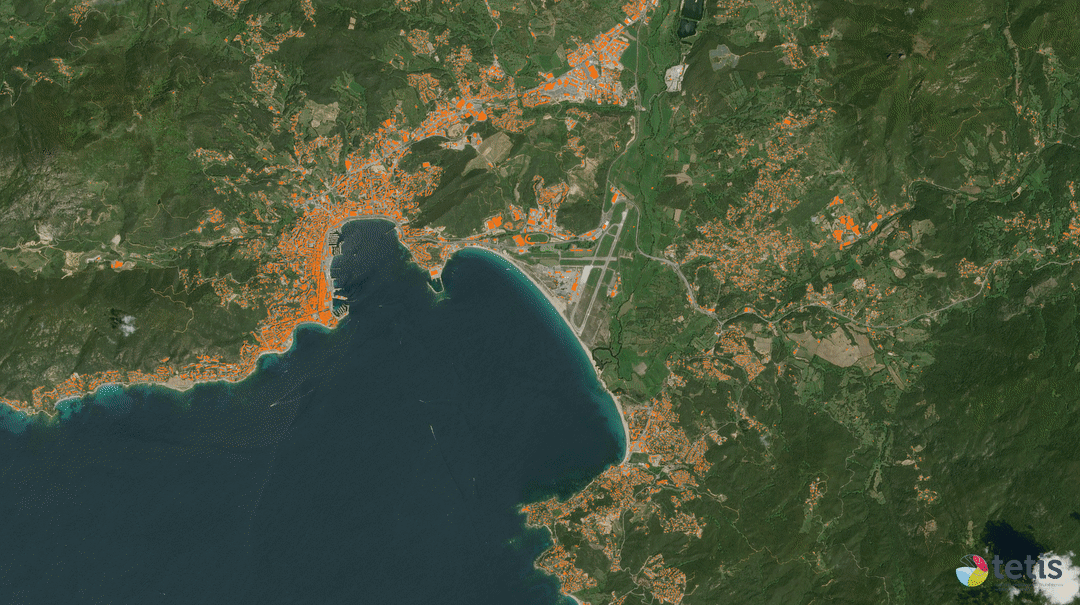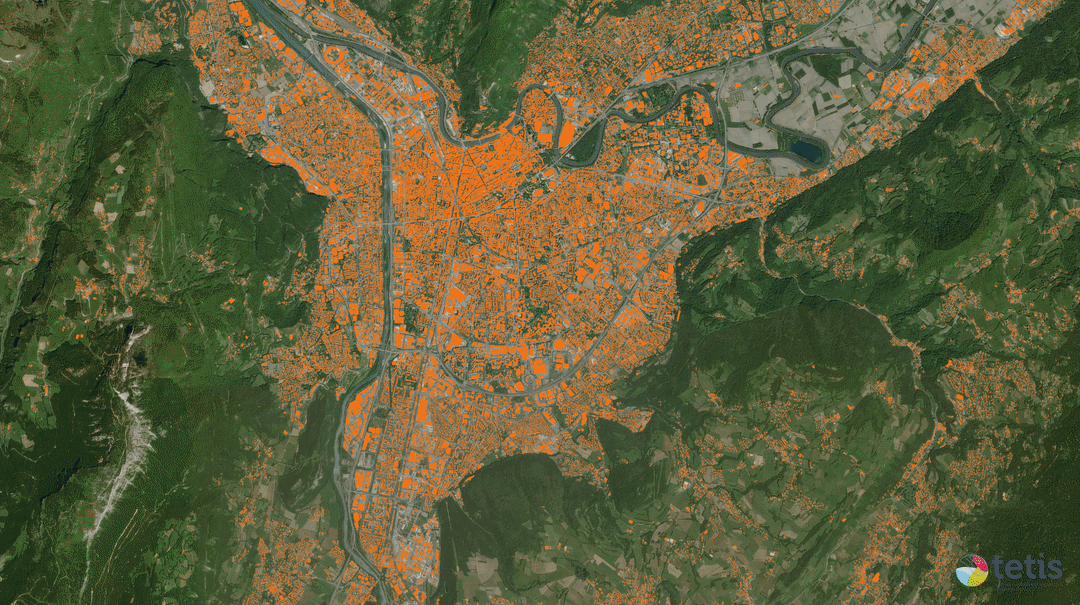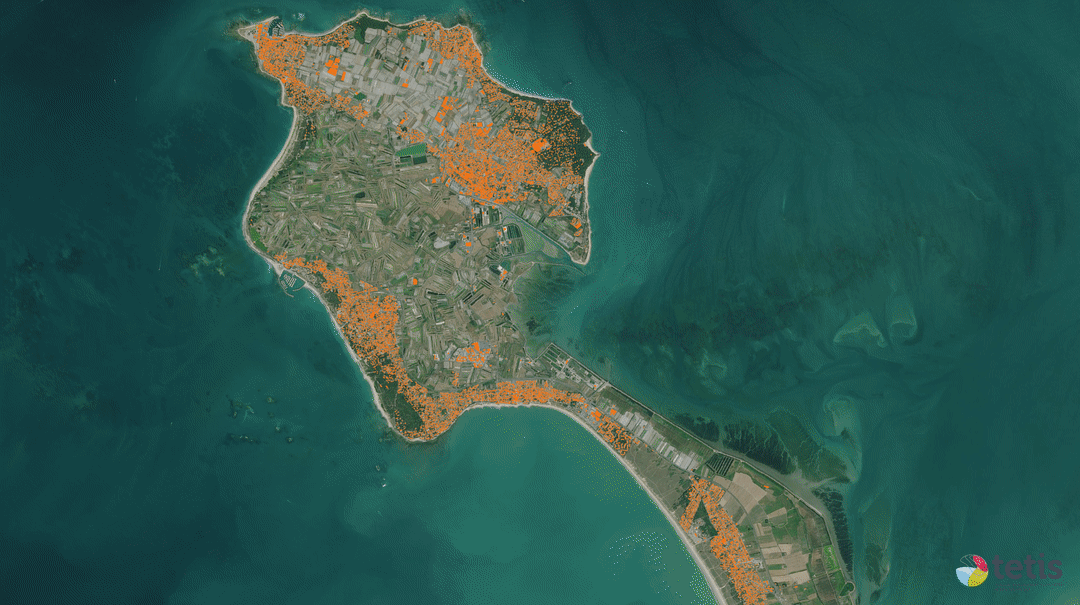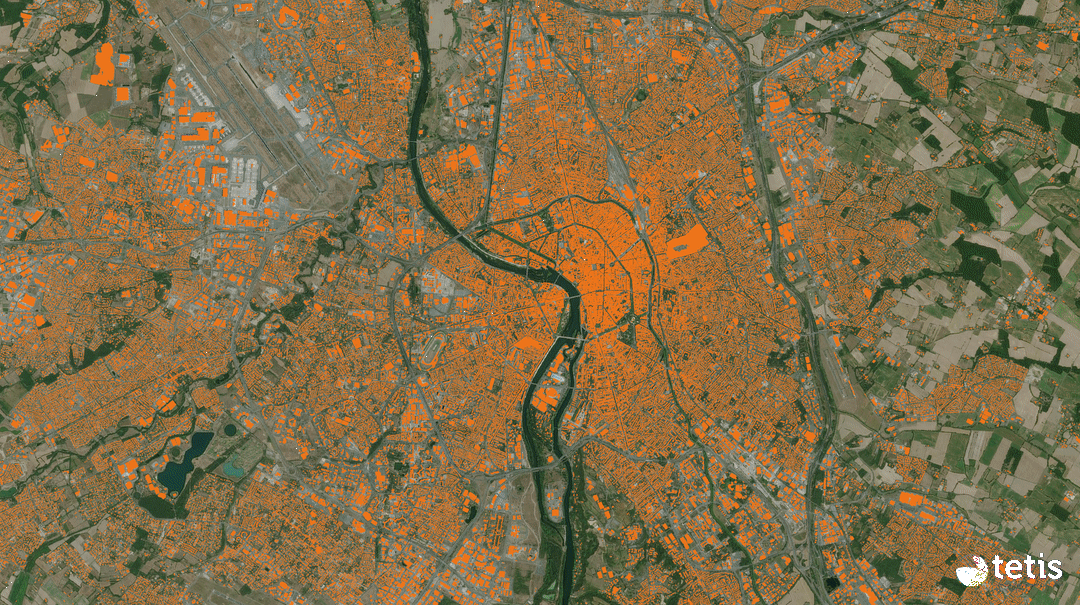
Données cartographiques : © Airbus Defence and Space, IGN, INRAE, IRD
Une méthode utilisant le Deep Learning
L’équipe de l’UMR TETIS a employé une technique d’apprentissage profond (deep learning) appelée « segmentation sémantique ». Cette technique consiste entraîner un réseau de neurones artificiels convolutionnel à classifier tous les pixels d’une image. Le réseau développé a été adaptée aux images Spot-6 et Spot-7, qui sont composées d’un canal panchromatique à 1.5 m de résolution spatiale, et de quatre canaux à 6 m de résolution spatiale (rouge, vert, bleu et proche infra-rouge).
L’originalité de cette architecture réside dans la façon dont celle-ci traite les canaux panchromatiques et multispectraux des images Spot-6 et Spot-7 : de façon unifiée, avec deux branches dédiées aux deux types d’images, traitées à leur résolution native. Le réseau fusionne l’information extraite aux deux échelles spatiales et estime les classes à la même résolution spatiale que l’image panchromatique, c’est-à-dire à 1.5 m.
Cela présente un double intérêt. D’une part, les images Spot-6 et Spot-7 peuvent être traitées directement, sans pré-traitement comme le pan-sharpening. Ces pré-traitements sont coûteux en temps de calcul et en stockage. D’autre part, le réseau préserve mieux l’information : en effet les pré-traitements comme le pan-sharpening peuvent introduire des distorsions dans les images, dégradant possiblement leur qualité et altérant l’information originale.
Pour entraîner et qualifier ce réseau, l’équipe a collecté plusieurs millions d’extraits d’images Spot-6 et Spot-7 sur les couvertures nationales acquises entre 2015 et 2019, et leur correspondance dans la BD TOPO fournie par l’IGN. Le volume de ces échantillons d’images représente moins de 1,4 % d’une couverture nationale pour le jeu de données utilisé pour l’apprentissage, et autant pour le jeu de données de validation.
L’équipe a ensuite entraîné le réseau. Puis, le jeu de données de validation a été utilisé pour calculer les métriques de précision au pixel (matrice de confusion, précision, rappel, f-score) sur chacune des scènes Spot-6 et Spot-7.
L’équipe a publié un chapitre entier détaillant la méthode [1]. Tous les outils permettant de mettre en œuvre la méthode sont en open-source, fondés notamment sur l’extension « OTBTF »[2] de la librairie Orféo ToolBox[3], ainsi que les librairies GDAL et TensorFlow.
L’importance du calcul haute performance
Le traitement de jeux de données volumineux requiert l’utilisation d’architectures matérielles de calcul scientifique spécifique. En particulier, le deep learning bénéficie largement des processeurs de type GPU (Graphical Processing Unit) qui permettent de paralléliser massivement les opérations élémentaires.
Pour pouvoir entraîner le réseau, conduire la validation, et produire les cartes, l’équipe de l’UMR TETIS a utilisé les ressources de calcul de la machine Jean-Zay installée à l’Institut du Développement et des Ressources en Informatique Scientifique (IDRIS). Jean-Zay est le nouveau supercalculateur acquis par le ministère de l’Enseignement supérieur, de la Recherche et de l’Innovation par l’intermédiaire de la société GENCI (Grand équipement national de calcul intensif). Plus d’un millier de scènes Spot-6 et Spot-7 ont pu être traitées avec le réseau, pour produire les cartes des bâtiments à 1.5 m de résolution spatiale sur tout le territoire Français métropolitain.
Résultats
Un jeu de données de validation a permis de mesurer les performances du réseau entraîné, sur des images non utilisées lors de l’apprentissage. Une matrice de confusion au pixel entre les classes « bâti » et « non-bâti » a été calculée sur chacune des scènes Spot-6 et Spot-7.
À partir de cette matrice de confusion, les métriques traditionnellement utilisées pour qualifier une classification ont été calculées. La précision, le rappel et le f-score ont ainsi été obtenus pour chaque classification de scène. Les statistiques des valeurs des métriques sur l’ensemble des scènes Spot-6/7 sont les suivantes :
| Métrique | Valeur moyenne | Écart type | Valeur médiane |
|---|---|---|---|
| Précision | 73.1 % | +/- 18.2 % | 79.6 % |
| Rappel | 68.8 % | +/- 10.0 % | 70.8 % |
| F-Score | 69.7 % | +/- 15.4 % | 74.4 % |
La figure ci-dessous montre la distribution des valeurs des différentes métriques considérées par scène.

Perspectives futures
Dans le cadre du projet TOSCA « Apport de l’Imagerie satellitaire Multi-Capteurs pour répondre aux Enjeux Environnementaux et sociétaux des socio-systèmes urbains », l’équipe de l’UMR TETIS s’intéresse à la distinction des différents types d’usage des bâtiments (e.g. résidentiel, commercial ou industriel, zones d’activités sportives, etc.).
Dans un futur proche, le modèle sera utilisé directement en pied d’antenne sur les images Spot-6 et Spot-7 issues du dispositif DINAMIS et alimentera le pôle THEIA avec ces produits. En termes de recherche et développement, le champ d’exploration reste vaste : en plus de l’exploration technologique et scientifique en deep learning, de nombreuses questions émergent dans le domaine de la géomatique : comment mieux utiliser les données de vérité terrain pour entraîner les modèles, et pour mieux qualifier les résultats ?
Contact

Rémi Cresson
INRAE | Tetis
@R.Cresson
Contributions
Références
- Cresson, R. 2020, Part 3 Semantic segmentation, Deep Learning for Remote Sensing Images with Open Source Software. CRC Press, pp 67-83
- Cresson R., 2019, A framework for remote sensing images processing using deep learning techniques, IEEE Geoscience and Remote Sensing Letters, Volume: 16, Issue: 1, Jan. 2019 , pp 25 – 29.
- Grizonnet, M., Michel, J., Poughon, V., Inglada, J., Savinaud, M., & Cresson, R. (2017). Orfeo ToolBox: open source processing of remote sensing images. Open Geospatial Data, Software and Standards, 2(1), 1-8.